深度神經網絡(DNN)是一種在輸入層和輸出層之間具有多個隱含層的神經網絡。與淺層ann相似,DNNs可以模擬複雜的非線性關係。
神經網絡的主要目的是接收一組輸入,對它們進行逐步複雜的計算,並給出輸出以解決實際問題,如分類。我們限制自己使用前饋神經網絡。
我們在一個深網絡中有一個輸入,一個輸出和一個序列數據流。
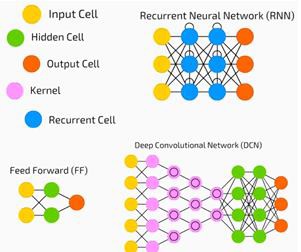
神經網絡廣泛應用於有監督學習和強化學習問題。這些網絡基於一組相互連接的層。
在深度學習中,隱藏層的數量,大多是非線性的,可以很大;比如說大約1000層。
DL模型比普通的ML網絡產生更好的結果。
我們主要採用梯度下降法對網絡進行優化和損失函數最小化。
我們可以使用Imagenet,一個數百萬數字圖像的存儲庫,將數據集分類爲貓和狗等類別。DL網絡除了用於靜態圖像之外,越來越多地用於動態圖像、時間序列和文本分析。
數據集的訓練是深度學習模型的重要組成部分。另外,反向傳播算法是訓練DL模型的主要算法。
DL處理具有複雜輸入輸出變換的大型神經網絡的訓練。
DL的一個例子是將照片映射到照片中的人的名字,就像他們在社交網絡上那樣,用短語描述圖片是DL的另一個最新應用。
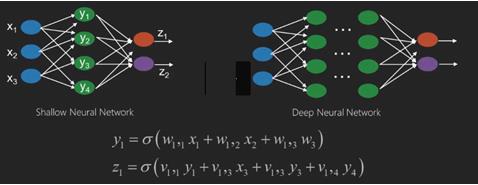
神經網絡是具有像x1、x2、x3等輸入的函數,在兩個(淺網絡)或幾個中間操作(也稱爲層(深網絡))中轉換爲像z1、z2、z3等輸出。
權重和偏差會隨著層的變化而變化。「w」和「v」是神經網絡各層的權值或突觸。
深度學習的最佳用例是有監督學習問題,在這裡,我們有大量的數據輸入和期望的輸出。
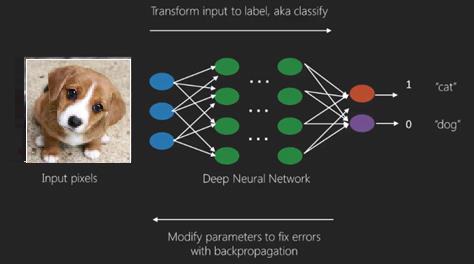
在這裡我們應用反向傳播算法得到正確的輸出預測。
深度學習最基本的數據集是MNIST,一個手寫數字集。
利用Keras對卷積神經網絡進行深度訓練,對該數據集中的手寫數字圖像進行分類。
神經網絡分類器的啓動或激活產生分數。例如,要將患者分爲病患和健康者,我們會考慮身高、體重和體溫、血壓等參數。
高分表示病人生病,低分表示病人健康。
輸出層和隱藏層中的每個節點都有自己的分類器。輸入層接受輸入並將其分數傳遞給下一個隱藏層以進行進一步的激活,這一直持續到達到輸出爲止。
這種從輸入到輸出的前進方向從左到右的過程稱爲前進傳播
神經網絡中的信用分配路徑(CAP)是從輸入到輸出的一系列變換。CAPs闡述了輸入和輸出之間可能的因果關係。
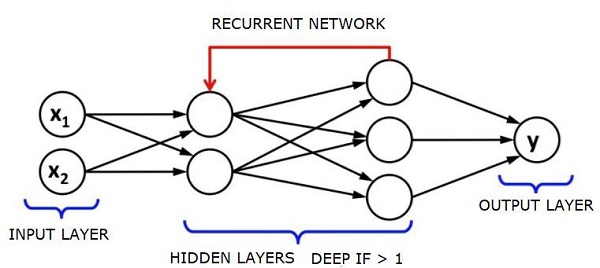
一個給定的前饋神經網絡的覆蓋深度,或者覆蓋深度是隱藏層的數量加上一個作爲輸出層。對於遞歸神經網絡,其中一個信號可以通過一個層傳播幾次,上限深度可能是無限的。
Deep Nets and Shallow Nets
淺層學習和深層學習沒有明確的深度閾值,但對於具有多個非線性層的深層學習,CAP必須大於2。
神經網絡中的基本節點是模仿生物神經網絡中神經元的感知。然後我們有多層感知或MLP。每一組輸入都由一組權重和偏差進行修改;每條邊都有一個唯一的權重,每個節點都有一個唯一的偏差。
神經網絡的預測精度取決於其權重和偏差
提高神經網絡精度的過程稱爲訓練,將前向支撐網的輸出與已知的正確值進行比較。
成本函數或損失函數是產生的產出與實際產出之間的差額。
訓練的目的是使數百萬個訓練實例的訓練成本儘可能小,爲此,網絡會調整權重和偏差,直到預測與正確的輸出匹配。
一旦訓練好,神經網絡每次都有可能做出準確的預測。
當模式變得複雜,你想讓你的計算機識別它們時,你必須使用神經網絡,在如此複雜的模式場景中,神經網絡的性能要優於其他競爭算法。
現在有GPU可以比以前更快地訓練他們。深層神經網絡已經在人工智慧領域掀起革命
事實證明,計算機擅長重複計算和遵循詳細的指令,但不善於識別複雜的模式。
如果存在簡單模式的識別問題,支持向量機(svm)或邏輯回歸分類器可以很好地完成這項工作,但隨著模式複雜度的增加,沒有辦法只能使用深層神經網絡。
因此,對於像人臉這樣的複雜模式,淺層神經網絡失效了,除了更深層的神經網絡之外別無選擇。深度網能夠通過將複雜的模式分解爲簡單的模式來完成它們的工作。例如,人臉;adeep網絡會使用邊緣來檢測嘴脣、鼻子、眼睛、耳朵等部位,然後將這些部位重新組合在一起形成人臉
正確預測的準確性變得如此精確,以至於最近在谷歌模式識別挑戰賽上,一個深網打敗了一個人。
這種由多層感知器組成的網絡的想法已經存在了一段時間;在這個領域,深層網絡模擬了人腦。但它的一個缺點是它們需要很長時間來訓練,這是一個硬體限制
然而,最近的高性能gpu能夠在一周內訓練出如此深的網;而快速的cpu可能需要數周甚至數月的時間來訓練。
Choosing a Deep Net
如何選擇深網?我們必須決定是要建立一個分類器,還是要在數據中尋找模式,以及是否要使用無監督學習。爲了從一組未標記的數據中提取模式,我們使用受限的Boltzman機器或自動編碼器。
在選擇深網時,請考慮以下幾點&負;
對於文本處理、情感分析、句法分析和名稱實體識別,我們使用遞歸網絡或遞歸神經張量網絡或RNTN;
對於任何在字符級運行的語言模型,我們都使用遞歸網。
對於圖像識別,我們使用深信度網絡DBN或卷積網絡。
對於目標識別,我們使用RNTN或卷積網絡。
對於語音識別,我們使用遞歸網絡。
一般來說,深度信念網絡和多層感知器都是很好的分類選擇。
對於時間序列分析,通常建議使用遞歸網。
神經網絡已經存在了50多年,但直到現在,它們才變得突出起來。原因是它們很難訓練;當我們試圖用反向傳播的方法訓練它們時,我們遇到了一個稱爲消失或爆炸梯度的問題。當這種情況發生時,訓練需要更長的時間,而準確度則居於次要地位。當訓練一個數據集時,我們不斷地計算成本函數,即一組標記的訓練數據的預測輸出和實際輸出之間的差異,然後通過調整權重和偏差值使成本函數最小化,直到得到最小值。訓練過程使用一個梯度,這個梯度是成本隨著權重或偏差值的變化而變化的速率。
Restricted Boltzman Networks or Autoencoders - RBNs
2006年,在解決梯度消失問題上取得了突破性進展。Geoff Hinton設計了一種新的策略,該策略導致了限制性Boltzman機器的發展——RBM,一種淺兩層網絡。
第一層是可見層,第二層是隱藏層。可見層中的每個節點都連接到隱藏層中的每個節點。網絡被稱爲受限的,因爲同一層中的兩個層不允許共享連接。
自動編碼器是將輸入數據編碼爲矢量的網絡。它們創建原始數據的隱藏或壓縮表示。向量在降維中是有用的;向量將原始數據壓縮成更小的基本維。自動編碼器與解碼器配對,允許根據其隱藏的表示重建輸入數據。
RBM在數學上等同於雙向翻譯。前向傳遞接受輸入並將其轉換爲一組對輸入進行編碼的數字。同時,一個向後的過程接受這組數字並將它們轉換回重構的輸入。訓練有素的網以高度的準確性進行後支撐。
在這兩個步驟中,權重和偏差都起著關鍵作用;它們有助於RBM解碼輸入之間的相互關係,並決定哪些輸入對檢測模式至關重要。通過向前和向後傳遞,訓練RBM用不同的權值和偏差重新構造輸入,直到輸入和構造儘可能接近爲止。成果管理制的一個有趣的方面是,數據無需標記。事實證明,這對於照片、視頻、聲音和傳感器數據等真實世界的數據集非常重要,而這些數據往往都是未標記的。RBM不需要人工標註數據,而是自動對數據進行排序;通過適當調整權重和偏差,RBM能夠提取重要特徵並重構輸入。RBM是特徵提取神經網絡家族的一部分,用於識別數據中的固有模式。這些也被稱爲自動編碼器,因爲它們必須編碼自己的結構。

Deep Belief Networks - DBNs
將RBMs與智能訓練方法相結合,形成了深度信任網絡(DBNs)。我們有一個新的模型,最終解決了梯度消失的問題。Geoff Hinton發明了RBMs和深度信念網作爲反向傳播的替代品。
DBN在結構上類似於MLP(多層感知器),但在訓練方面卻有很大的不同。正是這種培訓使DBNs能夠超越其膚淺的對手
DBN可以可視化爲一個RBM堆棧,其中一個RBM的隱藏層是其上面RBM的可見層。訓練第一個RBM以儘可能準確地重構其輸入。
將第一RBM的隱層作爲第二RBM的可見層,利用第一RBM的輸出對第二RBM進行訓練。這個過程被疊代,直到網絡中的每一層都得到訓練。
在DBN中,每個RBM學習整個輸入。DBN的全局工作原理是,隨著模型的緩慢改進(就像照相機鏡頭慢慢聚焦圖片一樣),對整個輸入進行連續微調。由於多層感知器MLP優於單一感知器,因此一組RBM優於單一RBM。
在此階段,RBMs檢測到數據中的固有模式,但沒有任何名稱或標籤。爲了完成DBN的訓練,我們必須在模式中引入標籤,並使用監督學習對網絡進行微調。
我們需要一個非常小的標記樣本集,這樣特徵和模式就可以與一個名稱相關聯。這一小部分有標籤的數據用於訓練。與原始數據集相比,這組標記數據可能非常小。
重量和偏倚略有改變,導致網絡對模式的感知發生了微小的變化,而且總的準確度通常略有提高。
與淺網相比,利用gpu可以在合理的時間內完成訓練,得到了非常精確的結果,並給出了消失梯度問題的解。
Generative Adversarial Networks - GANs
生成性對抗網絡是由兩個網絡組成的深層神經網絡,一個網絡對另一個網絡,因此被稱爲「對抗性」網絡。
2014年,蒙特婁大學(University of Montreal)的研究人員發表了一篇論文,介紹了GANs。Facebook的人工智慧專家YannLecun提到了GANs,他稱對抗性訓練是「過去10年裡ML最有趣的想法」
GANs的潛力是巨大的,因爲網絡掃描可以學習模擬任何數據分布。甘斯可以被教導在任何領域創造與我們相似的平行世界:圖像、音樂、演講、散文。他們在某種程度上是機器人藝術家,他們的作品令人印象深刻。
在GAN中,一個稱爲生成器的神經網絡生成新的數據實例,而另一個稱為鑑別器,則評估它們的真實性。
假設我們正在嘗試生成手寫數字,比如MNIST數據集中的數字,它取自真實世界。當從真實MNIST數據集中顯示實例時,鑑別器的工作是將它們識別爲真實的。
現在考慮一下GAN的以下步驟−
生成器網絡以隨機數的形式接收輸入並返回圖像。
生成的圖像與從實際數據集獲取的圖像流一起作為鑑別器網絡的輸入。
鑑別器接收真實和假的圖像,並返回機率,一個介於0和1之間的數字,1表示對真實性的預測,0表示假的。
所以你有一個雙反饋迴路;
鑑別器處於一個反饋迴路中,與我們所知道的圖像的基本真實性有關。
發生器與鑑別器處於反饋迴路中。
Recurrent Neural Networks - RNNs
RNN是一種數據可以向任何方向流動的神經網絡。這些網絡用於語言建模或自然語言處理(NLP)等應用。
RNNs的基本概念是利用序列信息。在一般的神經網絡中,所有的輸入和輸出都是相互獨立的。如果我們想預測一個句子中的下一個單詞,我們必須知道哪個單詞在它之前出現。
RNN被稱爲遞歸的,因爲它們對序列的每個元素重複相同的任務,而輸出是基於前面的計算。因此,可以說rnn有一個「內存」,它捕獲關於先前計算過的內容的信息。理論上,RNNs可以在很長的序列中使用信息,但實際上,它們只能回顧幾步。
長期短期記憶網絡(LSTMs)是最常用的rnn。
與卷積神經網絡一起,RNNs被用作模型的一部分來生成未標記圖像的描述。這件事看起來很管用,真是太不可思議了。
Convolutional Deep Neural Networks - CNNs
如果我們增加一個神經網絡的層數以使它更深,它會增加網絡的複雜性,並允許我們對更複雜的函數進行建模。然而,權重和偏差的數量將成倍增加。事實上,學習這些難題對於普通的神經網絡來說是不可能的。這就引出了一個解決方案,卷積神經網絡。
CNNs被廣泛應用於計算機視覺,也被應用於自動語音識別的聲學建模。
卷積神經網絡背後的思想是通過圖像的「移動濾波器」的思想。該移動濾波器或卷積適用於節點的特定鄰域,例如,該鄰域可以是像素,其中所應用的濾波器是節點值的0.5 x負;
著名的研究人員YannLecun開創了卷積神經網絡。Facebook作爲面部識別軟體使用這些網絡。CNN一直是機器視覺項目的解決方案。卷積網絡有許多層。在Imagenet挑戰賽中,2015年,一台機器能夠在物體識別方面擊敗人類。
簡單地說,卷積神經網絡是一種多層神經網絡。這些層有時多達17個或更多,並且假設輸入數據是圖像。
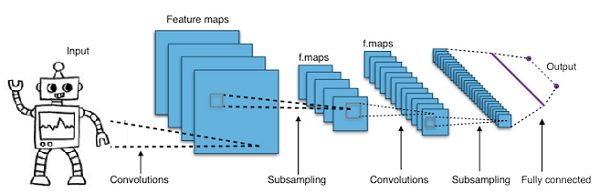
CNNs大大減少了需要調整的參數數量。因此,CNNs有效地處理了原始圖像的高維性。