反向傳播通過使用計算圖在諸如Tensorflow、Torch、Theano等深度學習框架中實現。更重要的是,理解計算圖上的反向傳播結合了幾種不同的算法及其變化,如時間反向傳播和具有共享權重的反向傳播。一旦所有東西都轉換成計算圖,它們仍然是相同的算法,只是計算圖上的反向傳播。
What is Computational Graph
計算圖被定義爲節點對應於數學運算的有向圖。計算圖是表示和計算數學表達式的一種方法。
例如,這裡有一個簡單的數學方程&負;
$$p = x+y$$
我們可以畫出上述方程的計算圖如下。
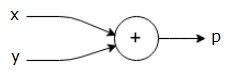
上面的計算圖有一個加法節點(帶有「+」符號的節點),它有兩個輸入變量x和y以及一個輸出變量q。
讓我們再舉一個稍微複雜一點的例子。我們有以下方程式。
$$g = \left (x+y \right ) \ast z $$
上面的方程由下面的計算圖表示。
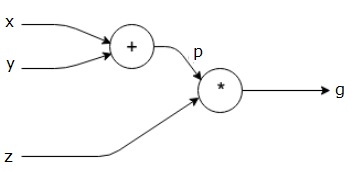
Computational Graphs and Backpropagation
計算圖和反向傳播都是神經網絡深度學習的重要核心概念。
Forward Pass
正向傳遞是計算圖表示的數學表達式的值的計算過程。執行forward pass意味著我們將變量的值從左(輸入)向右(輸出所在)正向傳遞。
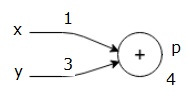
讓我們考慮一個例子,給出所有輸入的一些值。假設,爲所有輸入提供以下值。
$$x=1, y=3, z=−3$$
通過將這些值賦給輸入,我們可以執行前向傳遞,並爲每個節點上的輸出獲取以下值。
首先,我們使用x=1和y=3的值,得到p=4。
然後我們用p=4和z=-3得到g=-12。我們從左到右,向前走。
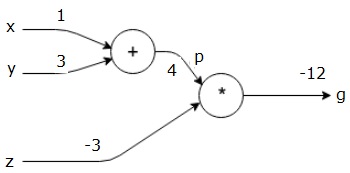
Objectives of Backward Pass
在反向過程中,我們的目的是計算每個輸入相對於最終輸出的梯度。這些梯度對於利用梯度下降訓練神經網絡是必不可少的。
例如,我們需要以下漸變。
Desired gradients
$$\frac{\partial x}{\partial f}, \frac{\partial y}{\partial f}, \frac{\partial z}{\partial f}$$
Backward pass (backpropagation)
我們通過找到最終輸出相對於最終輸出(本身)的導數來開始反向傳遞。因此,它將導致恆等式推導,並且該值等於1。
$$\frac{\partial g}{\partial g} = 1$$
我們的計算圖如下所示;
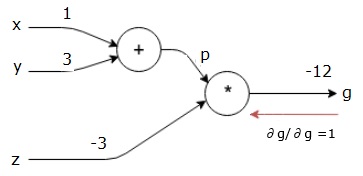
接下來,我們將通過「*」操作執行反向傳遞。我們將計算p和z的梯度,因爲g=p*z,我們知道&;
$$\frac{\partial g}{\partial z} = p$$
$$\frac{\partial g}{\partial p} = z$$
我們已經知道了z和p的值。因此,我們得到&負;
$$\frac{\partial g}{\partial z} = p = 4$$
and
$$\frac{\partial g}{\partial p} = z = -3$$
我們要計算x和y的梯度;
$$\frac{\partial g}{\partial x}, \frac{\partial g}{\partial y}$$
然而,我們想有效地做到這一點(儘管x和g在這個圖中只相差兩個跳,但假設它們彼此之間確實很遠)。爲了有效地計算這些值,我們將使用微分鏈規則。根據鏈式法則,我們有&;
$$\frac{\partial g}{\partial x}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial x}$$
$$\frac{\partial g}{\partial y}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial y}$$
但是我們已經知道dg/dp=-3,dp/dx和dp/dy很容易,因爲p直接依賴於x和y;
$$p=x+y\Rightarrow \frac{\partial x}{\partial p} = 1, \frac{\partial y}{\partial p} = 1$$
因此,我們得到&負;
$$\frac{\partial g} {\partial f} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial x} = \left ( -3 \right ).1 = -3$$
另外,對於輸入y&負;
$$\frac{\partial g} {\partial y} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial y} = \left ( -3 \right ).1 = -3$$
反向執行此操作的主要原因是,當我們必須計算x處的梯度時,我們只使用已計算的值和dq/dx(節點輸出相對於同一節點輸入的導數)。我們使用本地信息來計算全局值。
Steps for training a neural network
按照以下步驟訓練神經網絡&負;
對於數據集中的數據點x,我們用x作爲輸入進行正向傳遞,並計算出成本c作爲輸出。
我們從c開始反向傳遞,並計算圖中所有節點的梯度。這包括表示神經網絡權重的節點。
然後我們通過做W=W-學習率*梯度來更新權重。
我們重複此過程,直到滿足停止標準。