TIKA提取HTML文檔
下麵給出的是該程序用於從HTML文檔提取內容和元數據。
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.ParseContext; import org.apache.tika.parser.html.HtmlParser; import org.apache.tika.sax.BodyContentHandler; import org.xml.sax.SAXException; public class HtmlParse { public static void main(final String[] args) throws IOException,SAXException, TikaException { //detecting the file type BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(new File("example.htmll")); ParseContext pcontext = new ParseContext(); //Html parser HtmlParser htmlparser = new HtmlParser(); htmlparser.parse(inputstream, handler, metadata,pcontext); System.out.println("Contents of the document:" + handler.toString()); System.out.println("Metadata of the document:"); String[] metadataNames = metadata.names(); for(String name : metadataNames) { System.out.println(name + ": " + metadata.get(name)); } } }
保存上述代碼保存為HtmlParse.java,並通過使用下麵的命令從命令提示編譯:
javac HtmlParse.java java HtmlParse
下麵給出的是 example.htmll 文檔的快照。
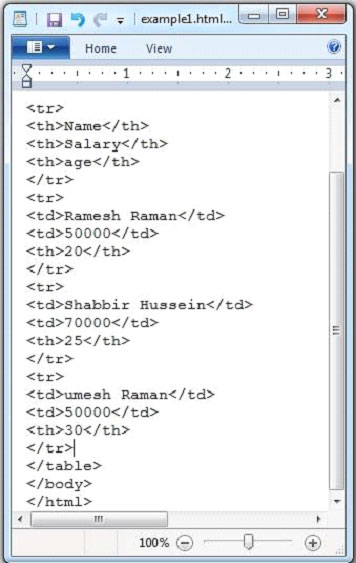
HTML文檔有以下屬性:
執行上述程序後,將得到下麵的輸出。
輸出:
Contents of the document: Name Salary age Ramesh Raman 50000 20 Shabbir Hussein 70000 25 Umesh Raman 50000 30 Somesh 50000 35 Metadata of the document: title: HTML Table Header Content-Encoding: windows-1252 Content-Type: text/html; charset=windows-1252 dc:title: HTML Table Header

