Hadoop HDFS
Hadoop文件係統使用分布式文件係統設計開發。它是運行在普通硬件。不像其他的分布式係統,HDFS是高度容錯以及使用低成本的硬件設計。
HDFS擁有超大型的數據量,並提供更輕鬆地訪問。為了存儲這些龐大的數據,這些文件都存儲在多台機器。這些文件都存儲以冗餘的方式來拯救係統免受可能的數據損失,在發生故障時。 HDFS也使得可用於並行處理的應用程序。
HDFS的特點
- 它適用於在分布式存儲和處理。
- Hadoop提供的命令接口與HDFS進行交互。
- 名稱節點和數據節點的幫助用戶內置的服務器能夠輕鬆地檢查集群的狀態。
- 流式訪問文件係統數據。
- HDFS提供了文件的權限和驗證。
HDFS架構
下麵給出是Hadoop的文件係統的體係結構。
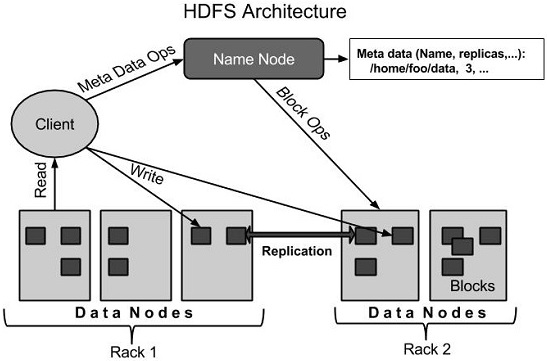
HDFS遵循主從架構,它具有以下元素。
名稱節點 - Namenode
名稱節點是包含GNU/Linux操作係統和軟件名稱節點的普通硬件。它是一個可以在商品硬件上運行的軟件。具有名稱節點係統作為主服務器,它執行以下任務:
- 管理文件係統命名空間。
- 規範客戶端對文件的訪問。
- 它也執行文件係統操作,如重命名,關閉和打開的文件和目錄。
數據節點 - Datanode
Datanode具有GNU/Linux操作係統和軟件Datanode的普通硬件。對於集群中的每個節點(普通硬件/係統),有一個數據節點。這些節點管理數據存儲在它們的係統。
- 數據節點上的文件係統執行的讀寫操作,根據客戶的請求。
- 還根據名稱節點的指令執行操作,如塊的創建,刪除和複製。
塊
一般用戶數據存儲在HDFS文件。在一個文件係統中的文件將被劃分為一個或多個段和/或存儲在個人數據的節點。這些文件段被稱為塊。換句話說,數據的HDFS可以讀取或寫入的最小量被稱為一個塊。缺省的塊大小為64MB,但它可以增加按需要在HDFS配置來改變。
HDFS的目標
-
故障檢測和恢複:由於HDFS包括大量的普通硬件,部件故障頻繁。因此HDFS應該具有快速和自動故障檢測和恢複機製。
-
巨大的數據集:HDFS有數百個集群節點來管理其龐大的數據集的應用程序。
-
數據硬件:請求的任務,當計算發生不久的數據可以高效地完成。涉及巨大的數據集特彆是它減少了網絡通信量,並增加了吞吐量。

